Codificación De Caracteres
Codificación de caracteres
Ascii
- Representa caracteres en inglés usando 7 bits (valores de 0 a 127).
- Ejemplo: La letra A tiene el valor decimal 65 en ASCII.
- Limitado: No soporta caracteres especiales ni alfabetos no latinos
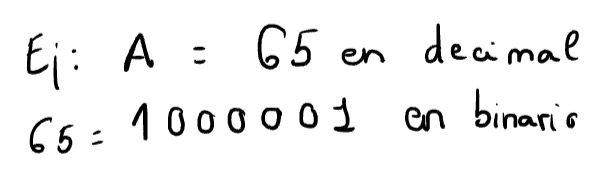
Ascii extendido
- Extiende ASCII a 8 bits (valores de 0 a 255).
- Soporta idiomas europeos básicos.
- Obsoleto en muchos casos frente a Unicode
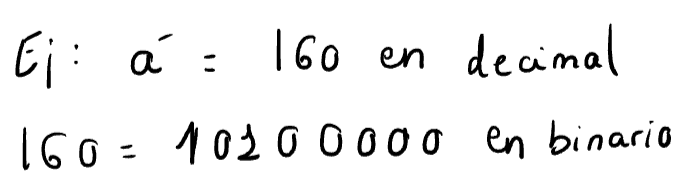
Unicode
Como solución a los problemas de que ningún conjunto de caracteres recogía todos los lenguajes mundiales, desde 1991 se ha acordado internacionalmente crear y utilizar la norma Unicode, que es una gran tabla, que en la actualidad asigna un código a cada uno de los más de cincuenta mil símbolos que posee, los cuales abarcan todos los alfabetos europeos, ideogramas chinos, japoneses, coreanos, muchas otras formas de escritura, lenguas muertas y más de un millar de símbolos especiales.
Este estándar es mantenido por el Unicode Technical Committee (UTC), integrado en el Unicode Consortium, del que forman parte con distinto grado de implicación empresas como: Microsoft, IBM, Oracle, SAP, Google, instituciones como la Universidad de Berkeley, y profesionales y académicos a título individual.
Unicode para cada carácter o símbolo especifica un nombre y un identificador numérico entero único (llamado el punto de código -code point-) además de otras informaciones necesarias para su uso correcto como la direccionalidad, capitalización y otros atributos.
Según su arquitectura, un ordenador utilizará bloques de 8, 16 o 32 bits para representar dichos números enteros. Las formas de codificación de Unicode reglamentan la forma en que los puntos de código se transformarán en unidades tratables por el computador.
Son tres las formas de codificación bajo el nombre UTF (Unicode Transformation Format - Formato de Transformación Unicode ):
- UTF-8 Codificación orientada a byte con símbolos de longitud variable. La más utilizada pero la más complicada para el ordenador.
- UTF-16 Codificación de 16 bits de longitud variable optimizada para la representación del plano básico multilingüe (BMP).
- UTF-32 Codificación de 32 bits de longitud fija, y la más sencilla de las tres.
✅ Unicode es el estándar que define un conjunto universal de caracteres (letras, números, símbolos, emojis, etc.) y asigna a cada uno un punto de código único (como U+0041 para “A” o U+1F600 para “😀”).
✅ UTF-8, UTF-16 y UTF-32 son formatos de codificación que especifican cómo se almacenan esos puntos de código en la memoria del ordenador. Cada uno usa una cantidad diferente de bytes para representar los caracteres:
- UTF-8 → Longitud variable (1 a 4 bytes).
- UTF-16 → Longitud variable (2 o 4 bytes).
- UTF-32 → Longitud fija (siempre 4 bytes).
📌 Analogía: Unicode es como un diccionario que asigna un número único a cada carácter, y UTF-8/UTF-16/UTF-32 son diferentes formas de escribir esos números en papel (o en la memoria del ordenador).
En Java, puedes representar caracteres Unicode con caracteres especiales de dos formas:
✅ 1. Escribiendo el carácter directamente (si tu teclado lo permite)
Si tu teclado tiene el carácter que necesitas, puedes simplemente escribirlo en el código:
char letra = 'ñ';
String texto = "¡Hola, señor!";
System.out.println(letra); // Salida: ñ
System.out.println(texto); // Salida: ¡Hola, señor!💡 Java usa UTF-16 internamente, por lo que no hay problema en manejar caracteres especiales directamente.
✅ 2. Usando la anotación Unicode (\uXXXX)
Si no puedes escribir el carácter directamente o quieres asegurarte de que se represente correctamente en cualquier sistema, puedes usar la notación \uXXXX, donde XXXX es el código Unicode en hexadecimal:
char letra = '\u00F1'; // Representa 'ñ'
String texto = "¡Hola, se\u00F1or!"; // "¡Hola, señor!"
System.out.println(letra); // Salida: ñ
System.out.println(texto); // Salida: ¡Hola, señor!🚀 ¿Cuándo usar cada opción?
- Si puedes escribir la letra directamente, es más fácil y legible.
- Si trabajas con caracteres no disponibles en el teclado o necesitas asegurarte de que el código se vea igual en cualquier sistema, usa
\uXXXX.
UTF-8
- Una codificación de Unicode.
- Es la más utilizada en aplicaciones web y sistemas modernos.
- Usa entre 1 y 4 bytes para representar caracteres:
- ASCII estándar usa 1 byte.
- •Caracteres como emojis o ideogramas (ej. chino) usan más bytes.•
- •Ejemplo: El carácter
éocupa 2 bytes (0xC3 0xA9)(hexa de cada byte).
UTF-16
Otra codificación de Unicode.
- Usa 2 o 4 bytes por carácter
- Menos eficiente que UTF-8 para textos con predominancia de caracteres ASCII
UTF-32
- Cada carácter ocupa exactamente 4 bytes.
- Más simple pero poco eficiente en términos de memoria
Base64
cualquier cadena puede ser convertida a Base64 ya que Base64 opera sobre los datos binarios subyacentes de la cadena y los representa en un formato de solo texto.
✅No hay límite de longitud, pero la salida será más grande (aproximadamente un 33% más que el original).