Árboles B Inserción Y División
Árboles B: Inserción y División
Inserción
Una inserción en un nodo de árbol B implica:
- Los elementos se insertan en una hoja (salvo excepciones).
- Si el nodo no es una hoja, tendremos que irnos al hijo más prometedor e intentarlo de nuevo
- La inserción en una hoja es un proceso sencillo, en el que se inserta de manera ordenada el valor en el array de claves
- Hay que respetar el grado del árbol: si al meter el elemento, el array de claves tiene demasiadas claves, hay que
dividir el nodo
En un árbol B dependiendo de la implementación se permite guardar elementos duplicados o no
Al insertar un elemento hay que tener en cuenta las propiedades de un árbol B vistas anteriormente, aquí te muestro un ejemplo de el número de hijos y de claves mínimos para diferentes árboles de grado 5, 6, y 7.
// acordarse que cuando es decimal
// el redondeo es hacia arriba
N = 5
- min punteros: N / 2 = 2.5 -> 3
- min claves: N / 2 - 1 = 1.5 -> 2
N = 6
- min punteros: N / 2 = 3
- min claves: N / 2 - 1 = 2
N = 7
- min punteros: N / 2 = 3.5 -> 4
- min claves: N / 2 - 1 = 2.5 -> 3
N = 5
- Max punteros: = 5
- max claves: 5 - 1 = 4
N = 6
- max punteros = 6
- min claves = 6 - 1 = 5
N = 7
- max punteros = 7
- min claves = 6Inserción en nodo hoja
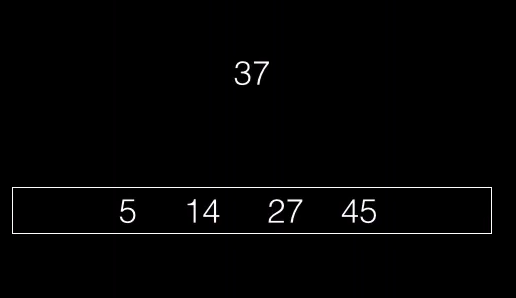
Cuando el nodo, es un nodo hoja, es tan fácil como recorrer las claves e introducir la nueva clave en la posición correcta (para que las claves sigan ordenadas)

Inserción en nodo con hijos
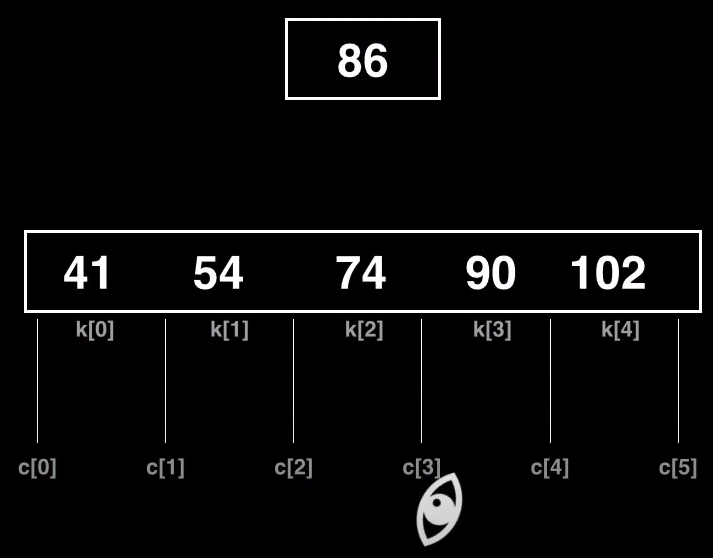
Si su nodo, no es un nodo hoja, no podemos realizar una inserción directa en ese nodo, en su lugar lo que hay que hacer es buscar para el nodo, el nodo hijo más prometedor y realizar esto de manera recursiva en el nuevo nodo elegido.
Buscamos cual es el nodo más prometedor, para ello se pueden definir distintos algoritmos para recorrer el árbol, por simplicidad se sigue mostrando como ejemplo la búsqueda linea.
Al igual que hacíamos en la búsqueda, iteramos sobre las claves accediendo a los hijos dependiendo de si la clave es mayor o menor que la siguiente. En este caso al llegar a la clave 90 y al ser mayor, accederíamos al hijo izquierdo de este cuyas claves son menores
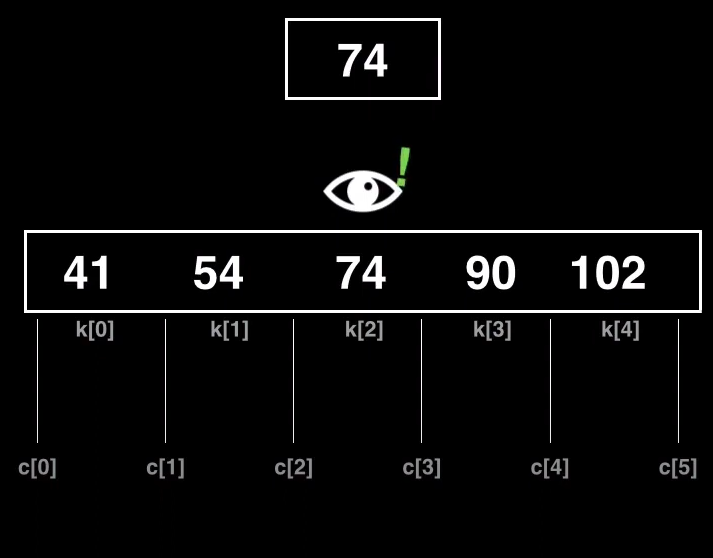
En el proceso de inserción podemos llegar al caso, en que la clave ya exista en el nodo. Y según como funcione nuestro árbol(si acepta duplicados o no) el comportamiento será diferente.
Árbol sin duplicados
En un árbol sin duplicados no se puede tener dos claves que tengan el mismo valor. Por lo tanto si nuestro árbol no acepta duplicados y nos encontramos en este caso, es que el nodo ya tiene una clave que vale igual a lo que queremos insertar, así que se rechaza la operación y se lanza una excepción dado que no se permite.
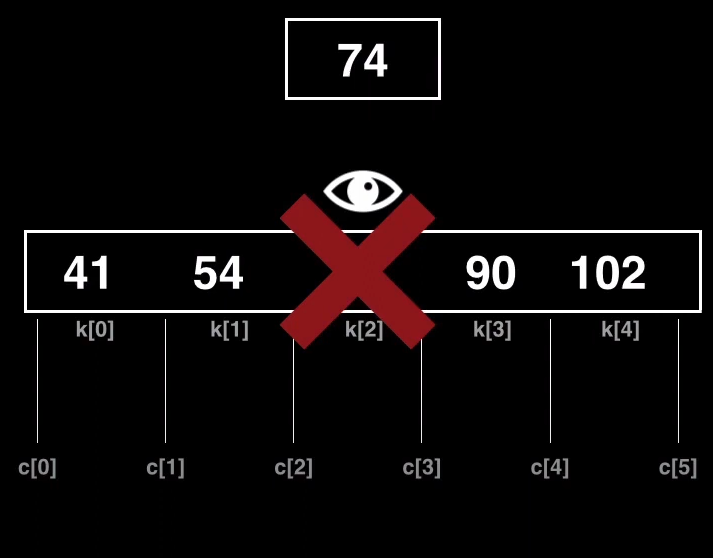
Árbol con duplicados
Un árbol que acepta duplicados es un árbol en el que puedes insertar múltiples ocurrencias de una misma clave dentro del árbol sin que pase nada.
Un aspecto interesante de la inserción con duplicado es que cuando decidimos cual es el nodo descendiente sobre el que tenemos que hacer la inserción, si somos consistentes, dará bastante igual si nos vamos por el hijo derecho o por el hijo izquierdo. Porque el descendiente izquierdo contendrá elementos entre 54 y 74 y el hijo derecho valores entre el 74 y el 90 que también nos vale, para ser consistentes siempre tendremos que tirar por la misma estrategia
Si sabemos que esto de que se repitan nodos se va a dar de manera frecuente quizás esta estrategia no sea la mejor
Dado que un árbol B es ideal cuando vamos a almacenar información en circunstancias en las que nos interesa es el menor número posible de accesos a disco para ir sacando la información. Por ejemplo los árboles B se usan mucho en base de datos donde cada uno de estos nodos es un sector del disco duro, el cual lleva un tiempo de acceso que aunque no sea mucho si que influye bastante en la operación de búsqueda y puede hacer que sea mucho más lenta la ejecución de una query.
Por esta razón insertar duplicados en un árbol lo hará crecer hacia abajo y lo único que provocará es que el número de nodos que hay que emplear para almacenar esta estructura crezca bastante, lo que se acaba traduciendo en un mayor espacio en disco y mayor tiempo de acceso, por otro lado aumenta la cantidad de operaciones de división al hacer que los nodos crezcan, y si podemos evitarlo pues será mejor.
En vez de estar insertando claves, nos sale mas economico tener un metadato adicional en nuestra estructura, en el que se indique el número de repeticiones que aparece una clave dentro de un nodo
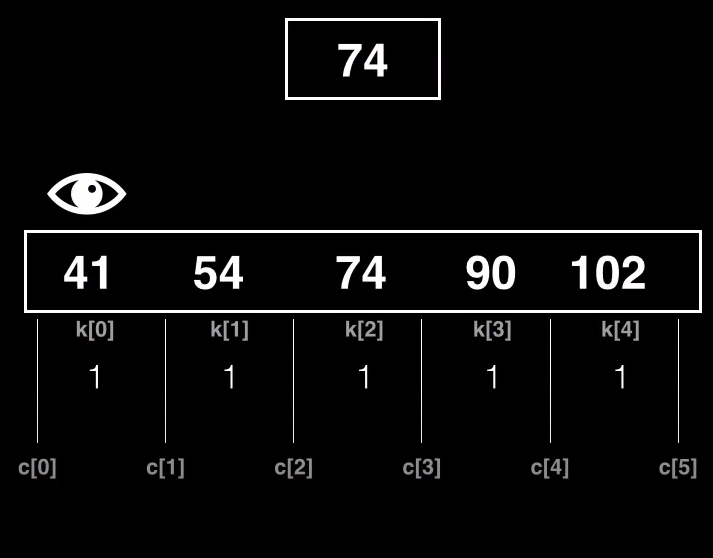
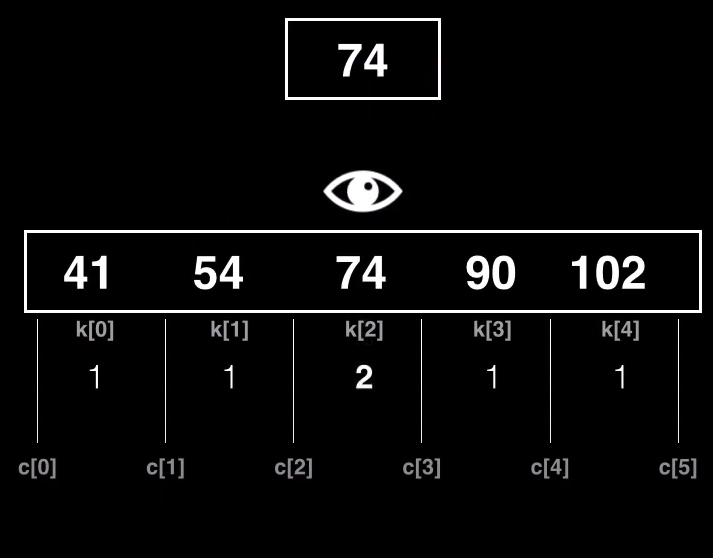
Ahora cada clave tiene el número de repeticiones de cada clave
Ahora cuando se encuentre una clave con ese valor, lo único que habría que hacer es actualizar el metadato de esa clave aumentando el número de repeticiones de esta
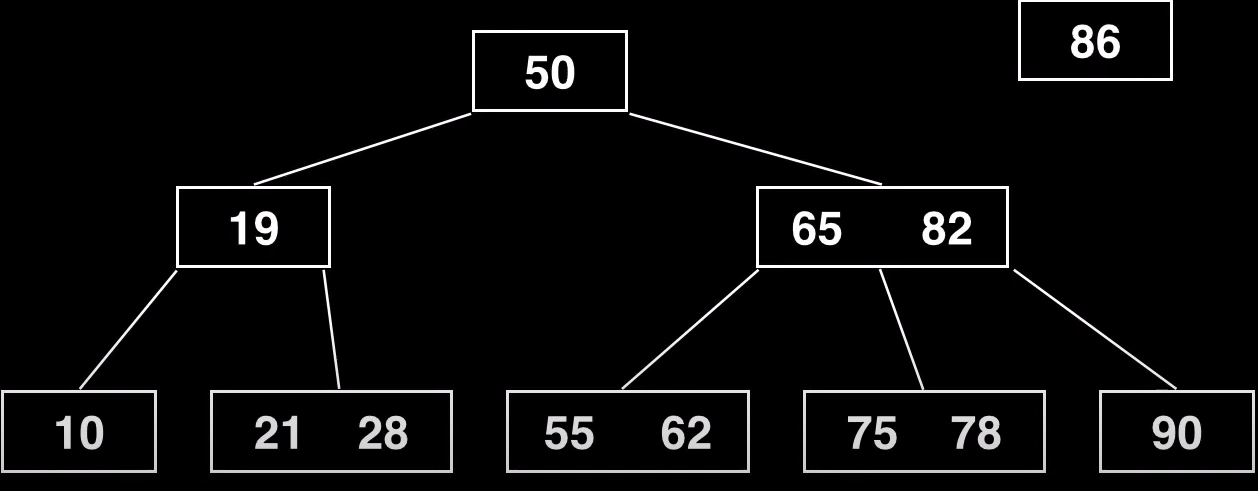
En este ejemplo queremos insertar el valor 86 en este árbol B
Buscamos cual es el nodo más prometedor, para ello se pueden definir distintos algoritmos para recorrer el árbol, por simplicidad se sigue mostrando como ejemplo la búsqueda linea. En este caso empezaríamos por la raíz recorriendo sus claves y accediendo a los hijos más prometedores
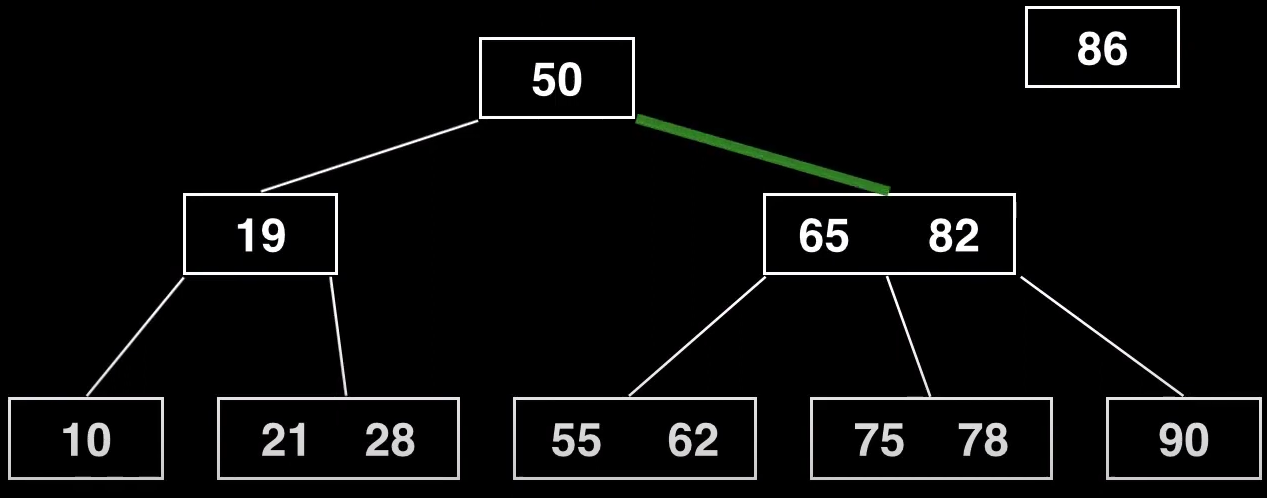
Empezamos por el nodo raíz y viajaremos por el hijo derecho dado que la clave a insertar es mayor que la clave del nodo raíz
Volvemos a realizar la misma operación de búsqueda en el nodo hijo. Y en este caso como todas las claves son mejores que la que queremos insertar, nos moveremos al hijo derecho de la última clave
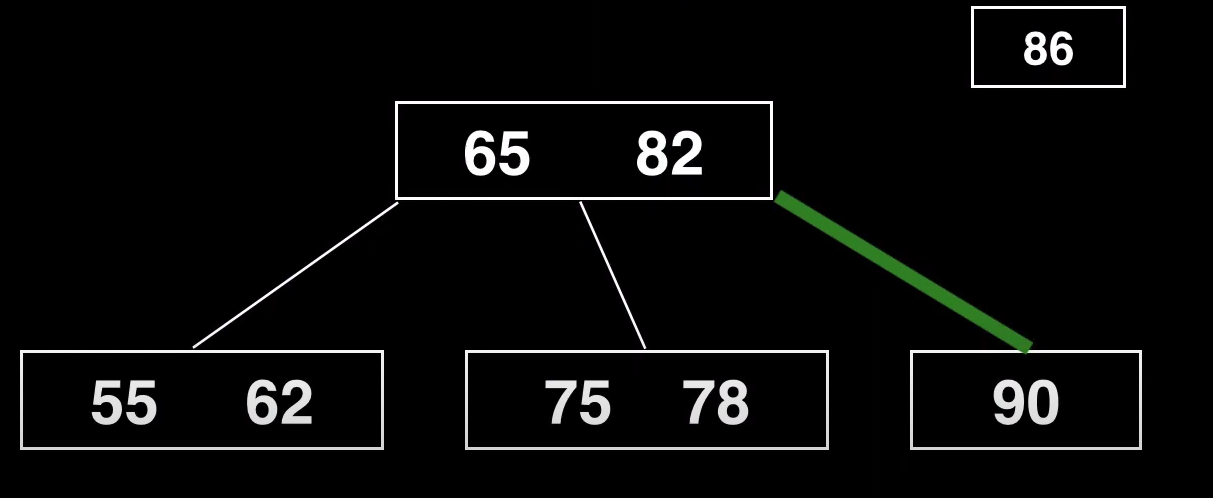
Al tratarse ya de un nodo hoja, insertamos el elemento

División
Aquí se explica en términos generales una forma de realizar la división, pero en código no se utiliza las siguientes formas, para ver la implementación de la división a utilizar, mirar en el apartado de pseudo código
N = orden
L = Lower = Mínimo de keys de este árbol
U = Upper = Máximo de keys para este árbol
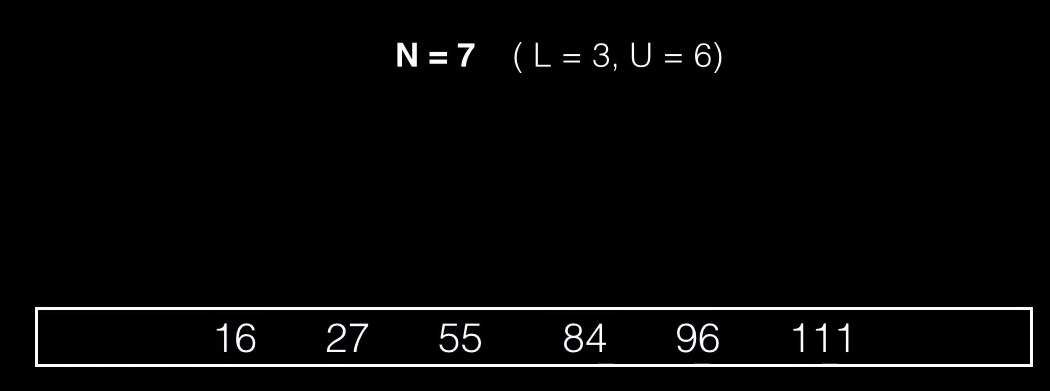
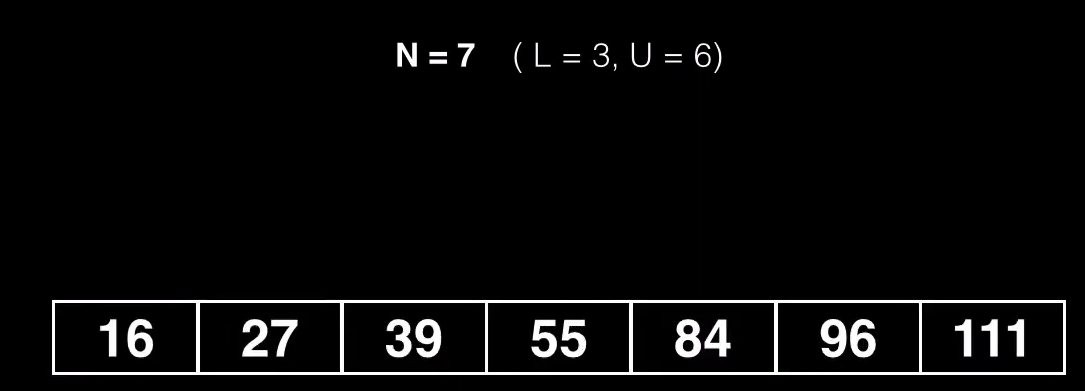
Imaginemos que queremos insertar una nueva clave en este nodo, pero el nodo ya tiene el máximo de keys permitidas
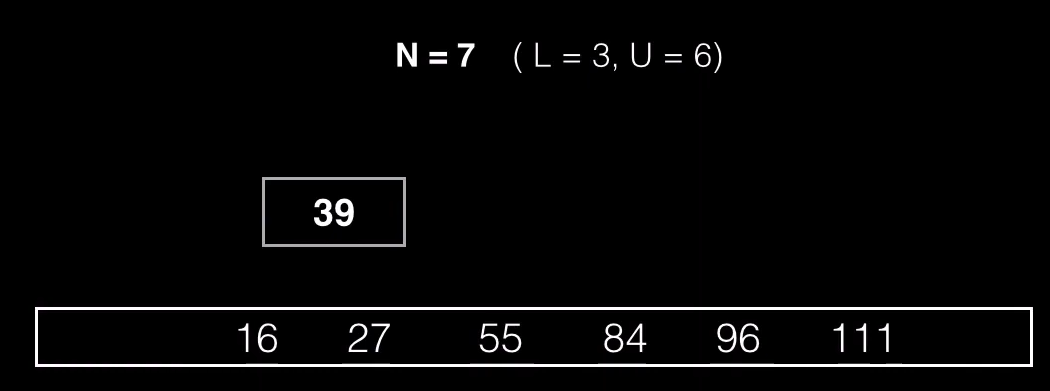
Ahora el nodo supera el máximo de claves permitidas
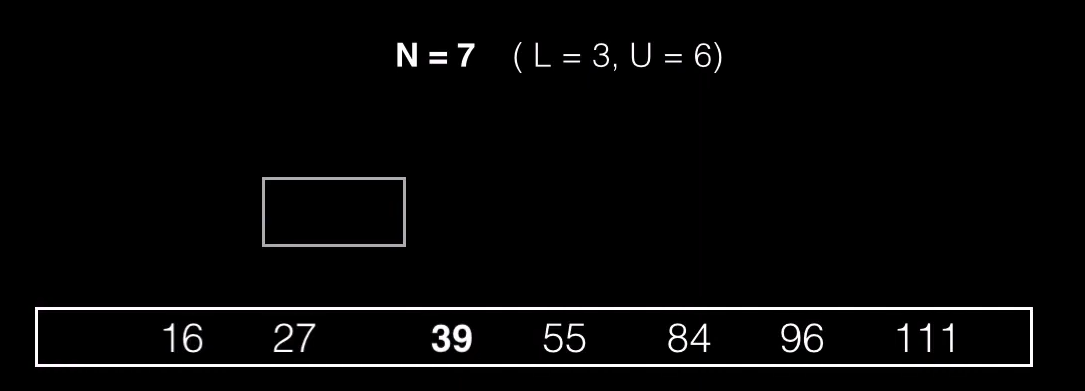
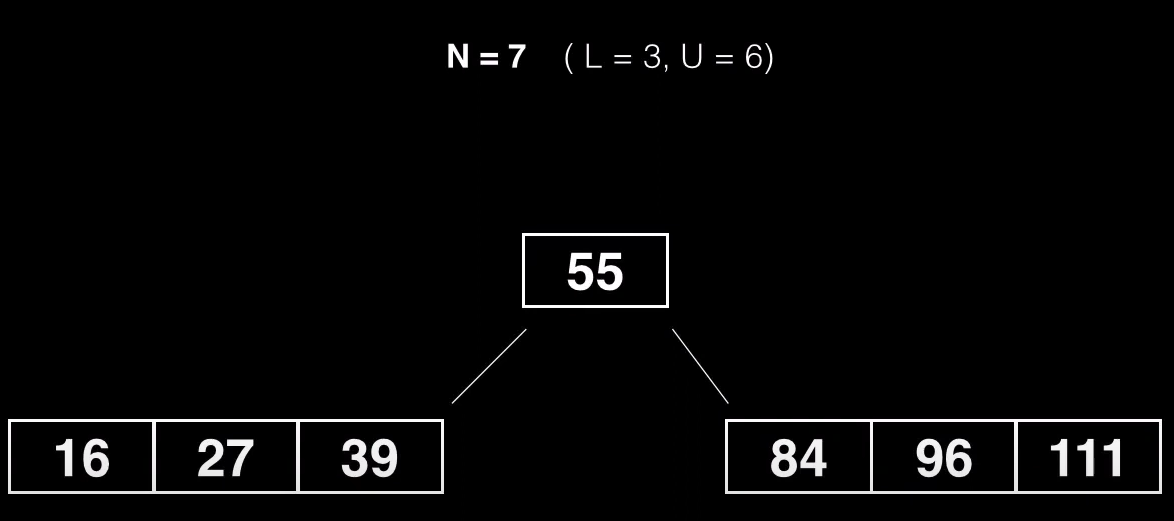
Para dividir el nodo buscamos un punto medio al que vamos a llamar pivote, y dividimos el nodo en otros dos subnodos, un subnodo contendrá elementos menores que el valor pivote y otro subnodo contendrá elementos mayores al pivote
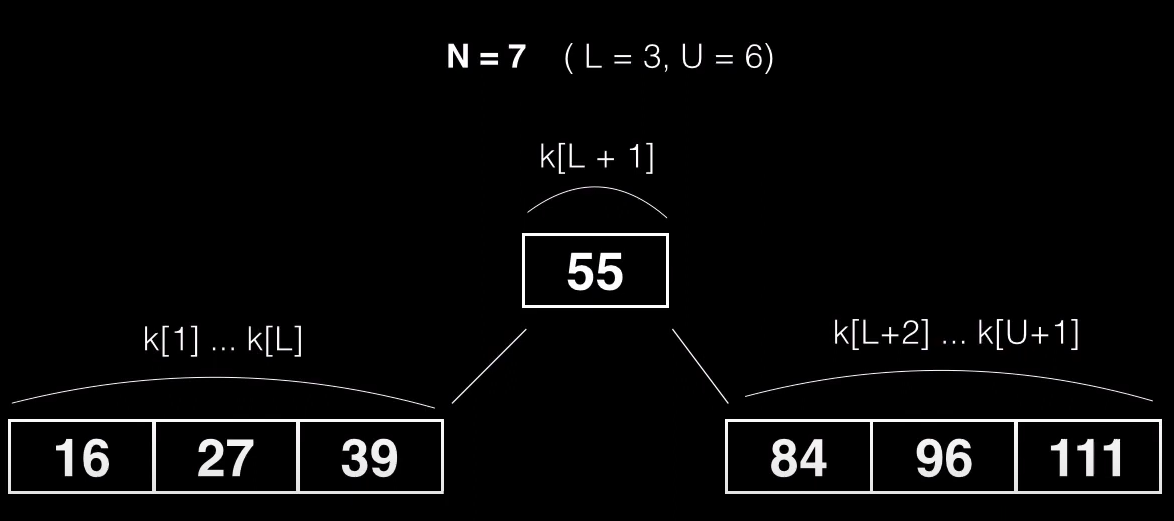
Como cada nodo resultante tiene que ser válido es evidente, que cada nodo tiene que tener el mínimo de claves permitidas (L) al menos.
Esto significa que la primera clave que se puede usar como pivote es L + 1 = K, por que eso significa que dejará los primeros L elementos como parte del primer subnodo. Por otra parte el subnodo derecho está formado por L + 2 hasta U + 1 (por que teniamos 6 claves máximas y ahora tenemos 7)
Normalmente nunca vamos a tener esta división tan rara como la que acabamos de hacer, por que nos sale mucho mas económico reutilizar uno de los nodos que ya tenemos y simplemente trasplantar las claves de uno de los subnodos a un nodo recién creado.
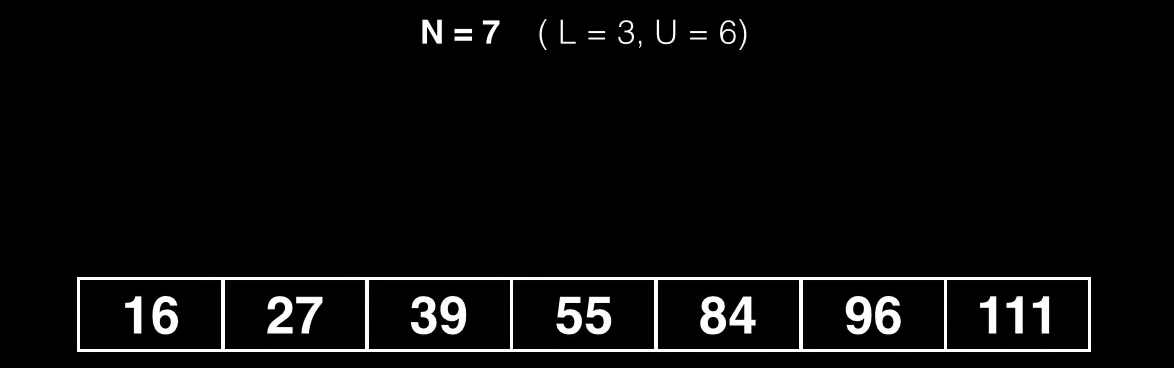
Una vez tengamos esos nodos transplantados en el nuevo nodo
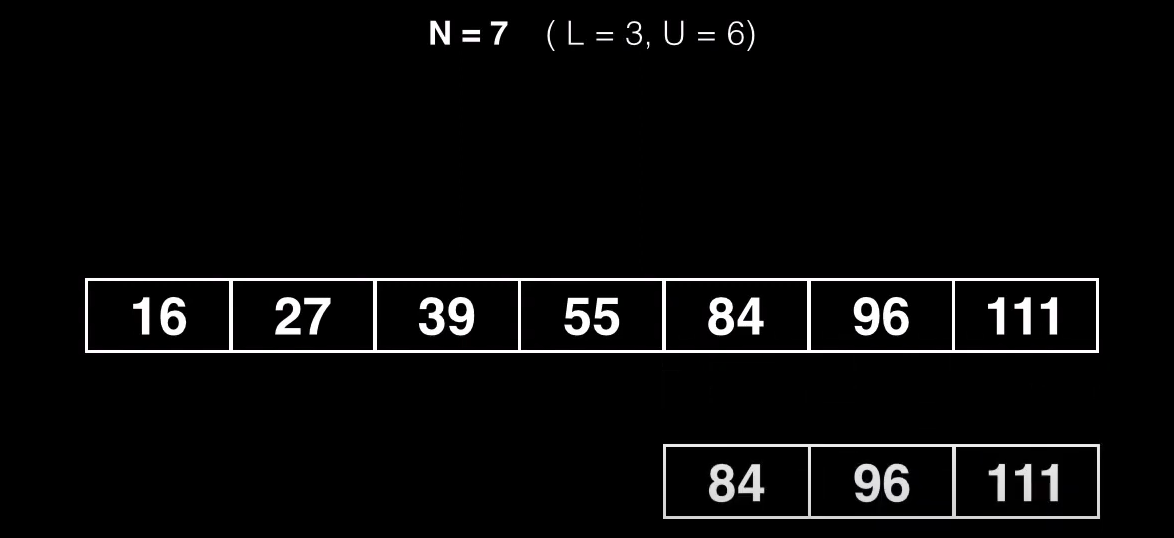
Los quitaremos del nodo principal
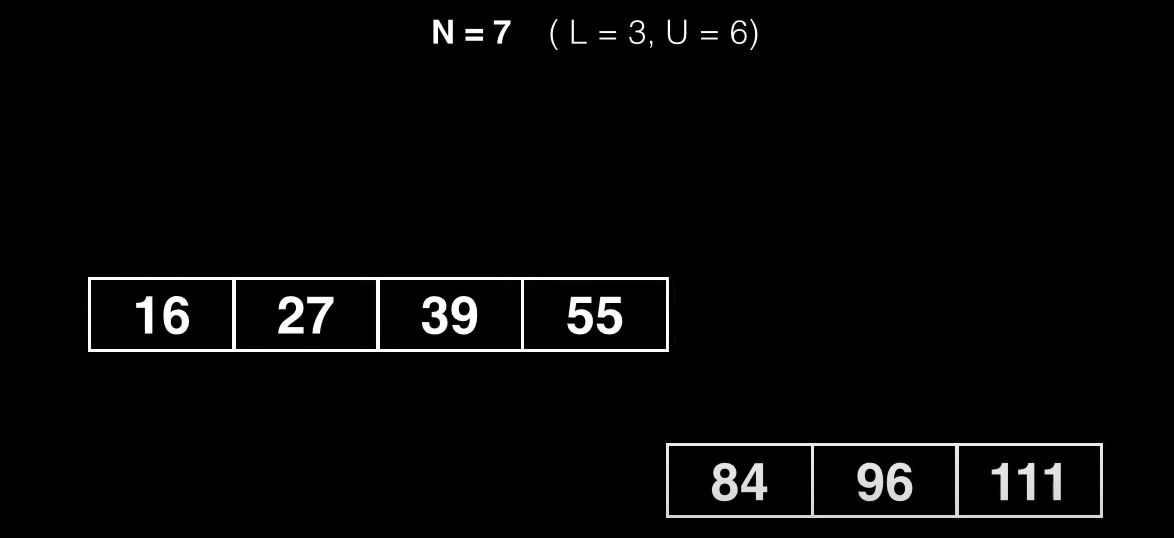
Luego separaremos del nodo, el pivote, que lo insertaremos como elemento nuevo dentro del nodo padre
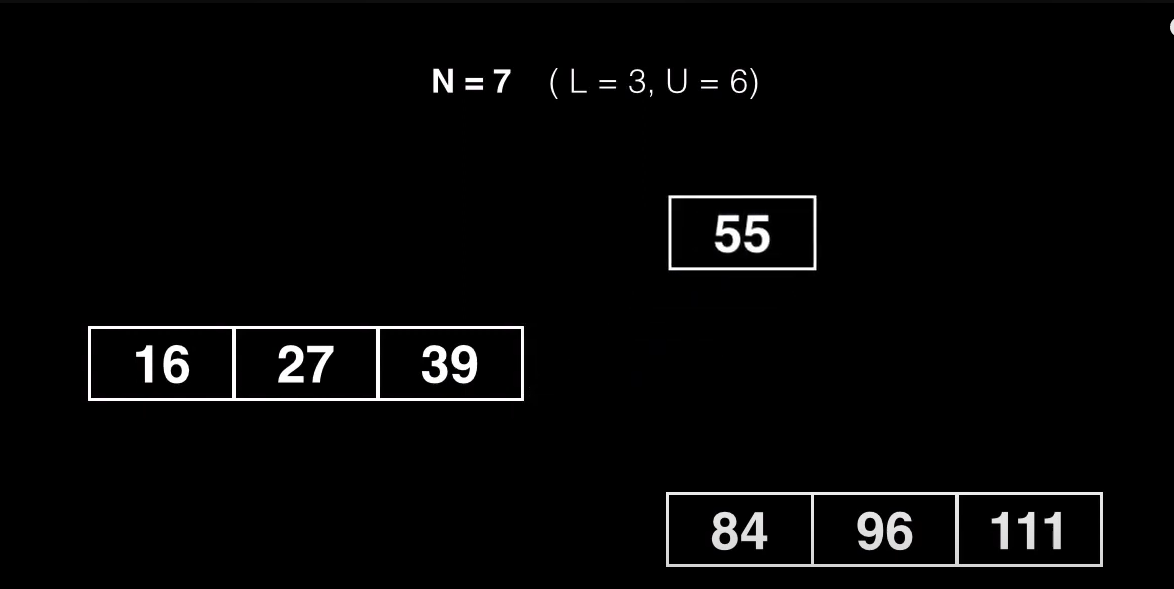
Hasta ahora hemos tratado a los arboles como una estructura recursiva, es que ahora tengo que guardar una referencia a los padres? La respuesta es no, hay un pequeño truco para enviar un elemento al padre sin tener que fabricar una referencia explicita que veremos en el pseudo código.
Inserción pivote (extremo del nodo padre)
Ejemplo:
Imaginamos que queremos insertar el valor 35 dentro de este árbol
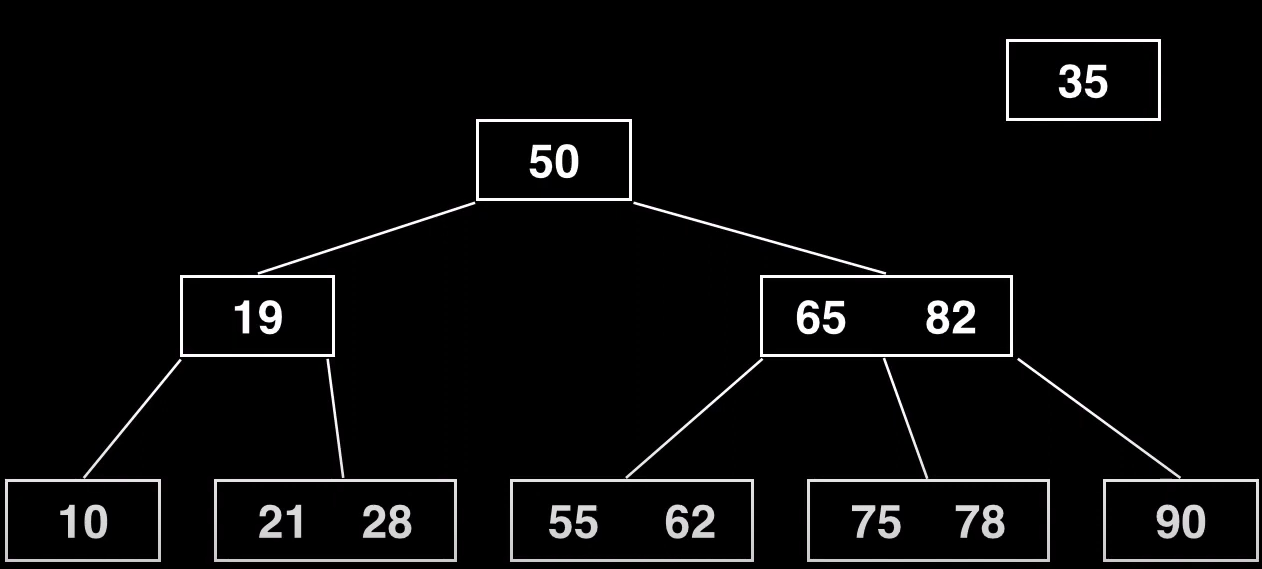
El árbol quedaría así, pero como tiene más claves de las permitidas habrá que hacer una division
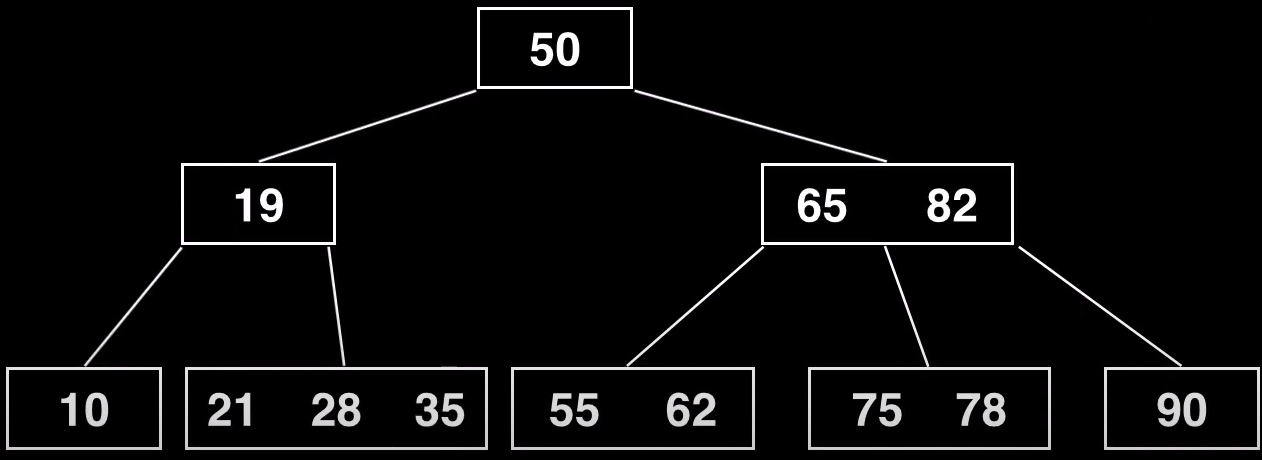
Al hacer la división, se forma un nuevo nodo (35) que de momento no enlaza con nada, y hemos sacado el pivote (28). Para terminar la división insertamos el 28 como nuevo elemento del nodo padre
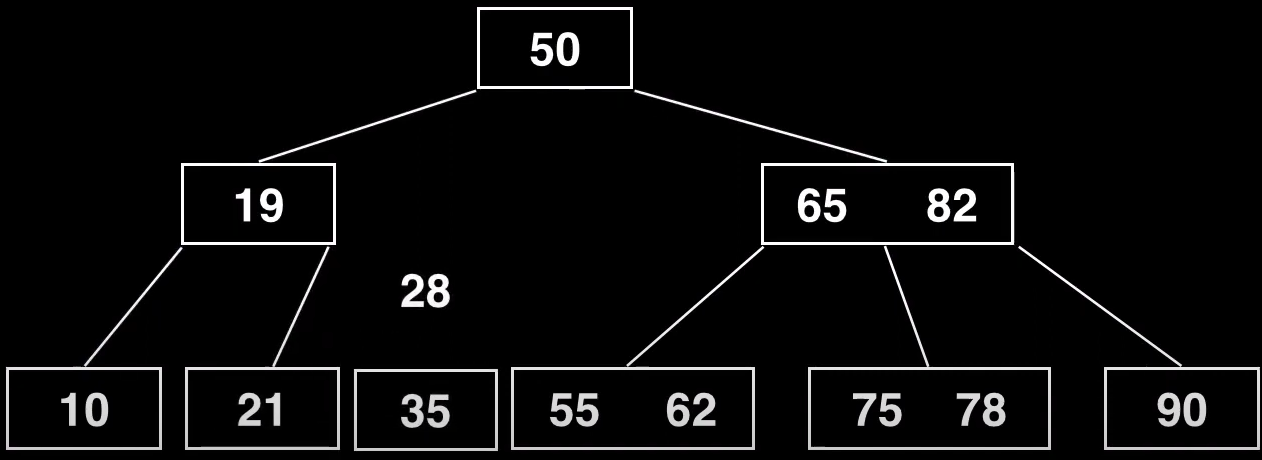
Como se muestra, primero se transfiere sin ningún puntero, el resto de elementos que ya estaban deben mantener sus referencias (tanto el hijo izquierdo como el derecho)
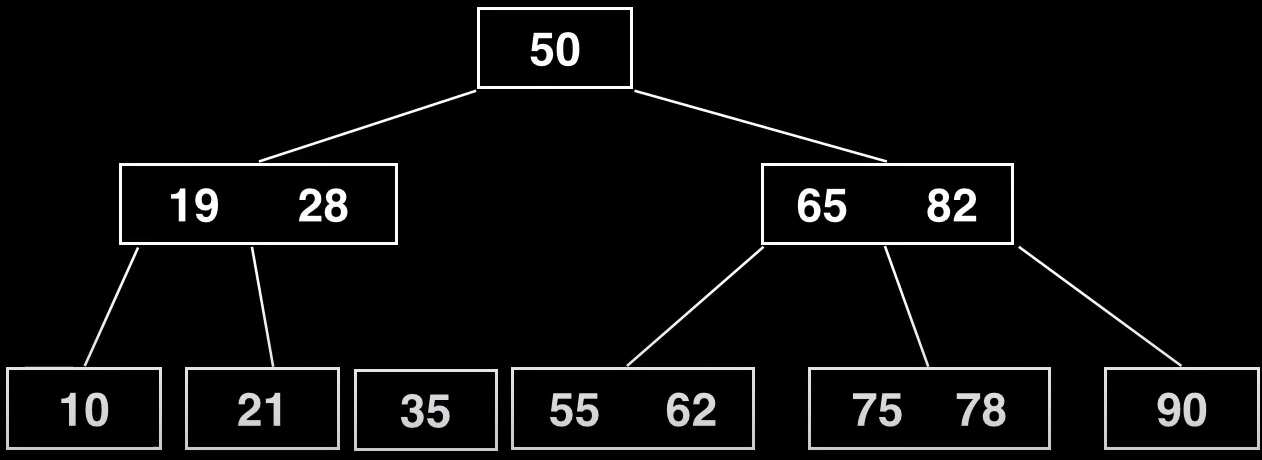
Por último conectamos el nuevo nodo, como hijo derecho del pivote
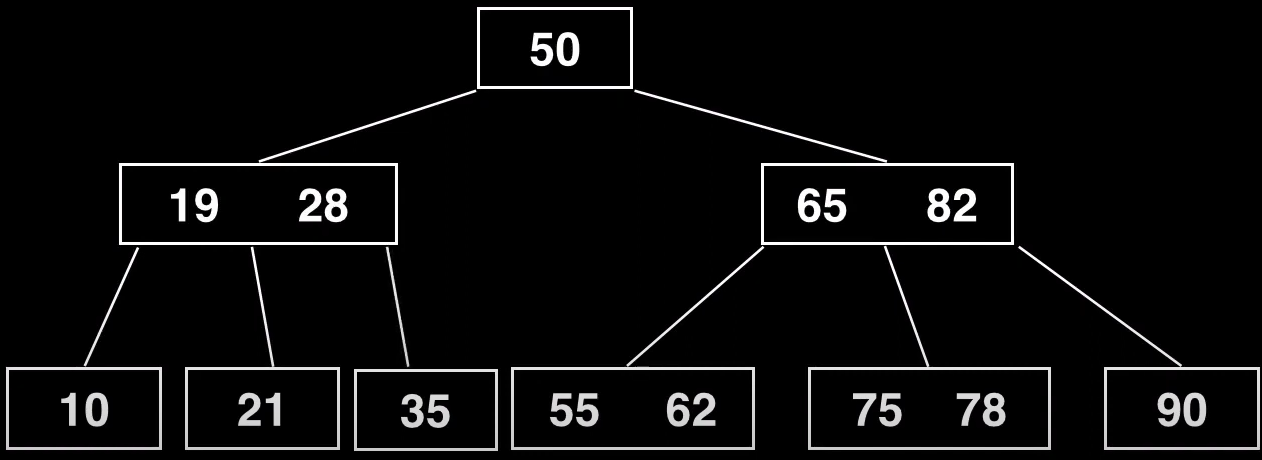
Inserción pivote (En medio del nodo padre)
Vamos a ver lo mismo pero ahora tendremos que insertar el pivote en medio de las claves del nodo padre:
Imaginemos que debemos insertar el valor 41 dentro de este nodo padre
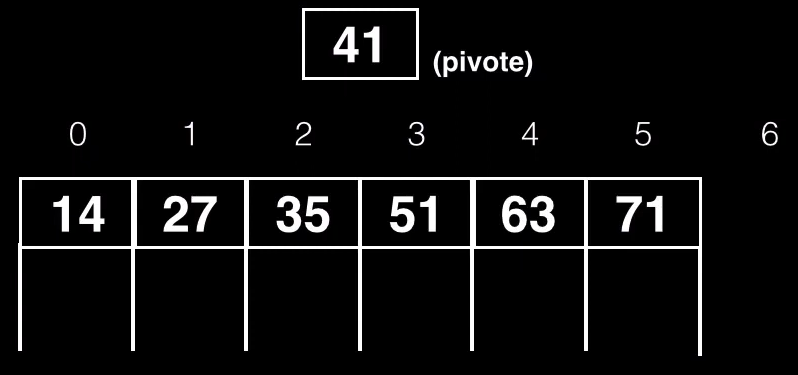
Debemos insertar la clave respetando el orden por lo que la clave 41 se insertará en la posición 3. Todas las claves de la derecha se verán desplazadas
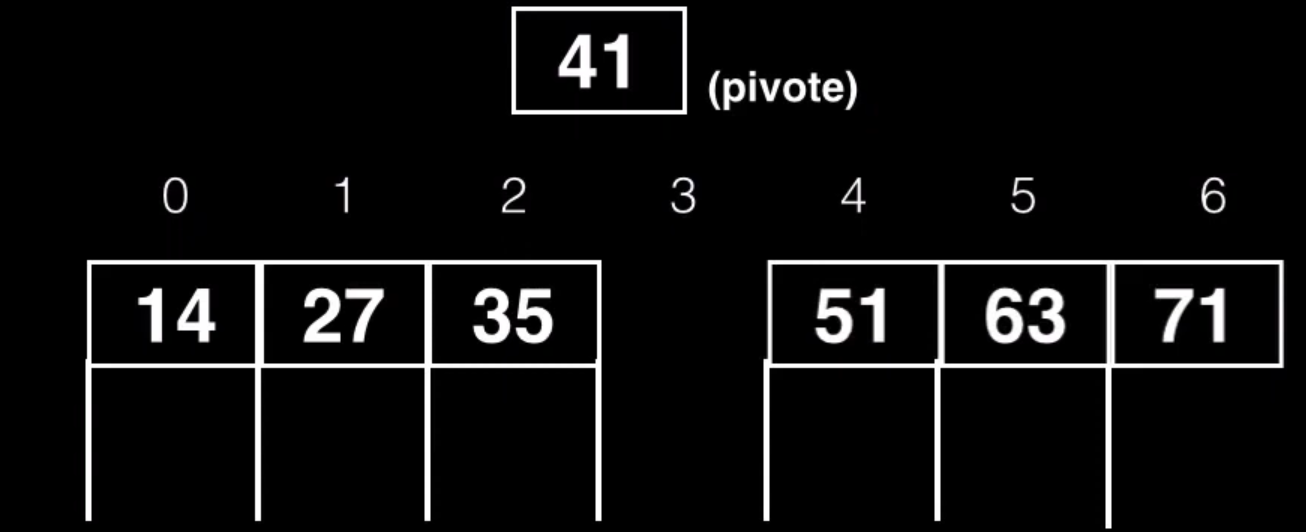
Pero también todos los hijos derechos deberán ser empujados una posición a la derecha
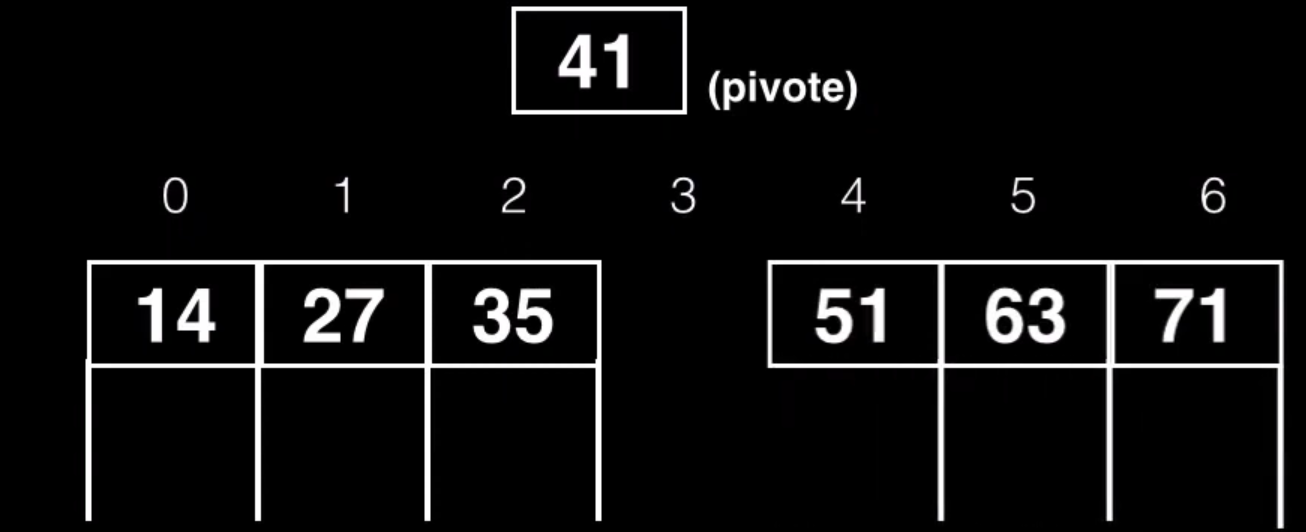
Entonces ya podremos meter el pivote
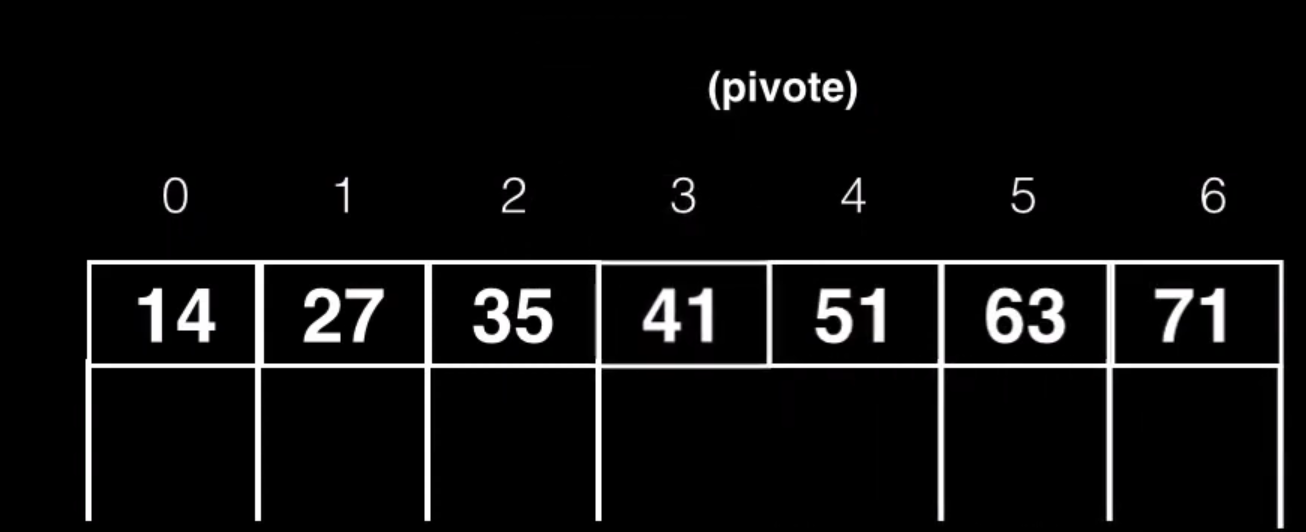
Por último pondremos el hijo derecho a la nueva clave creada (41)
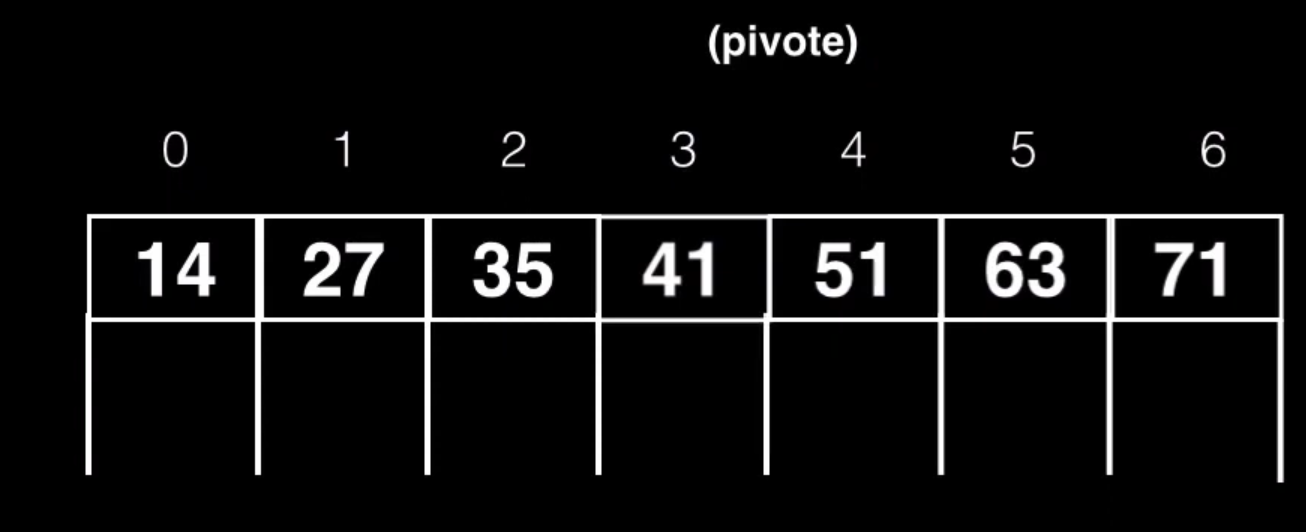
Hay que tener en cuenta que el nodo padre también puede tener más claves de las permitidas por culpa de la división realizada en alguno de sus hijos, por lo que este también deberá realizar una operación de división
En este otro ejemplo, que ha superado el máximo de claves permitidas, es necesario realizar una división
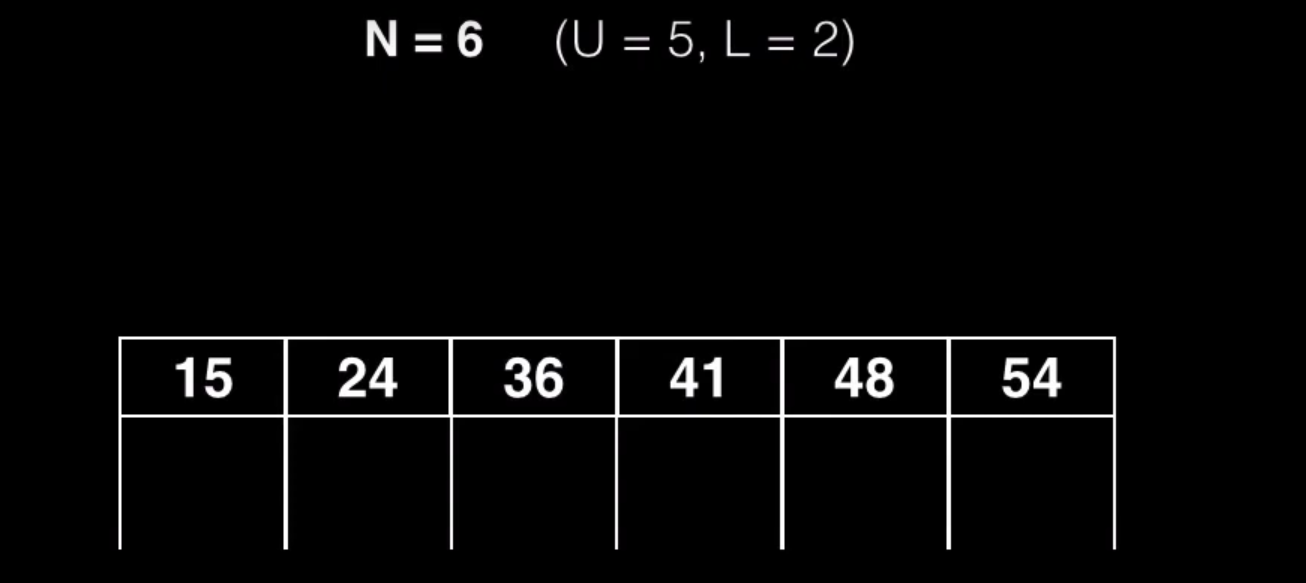
El pivote en este caso es L + 1 que en este caso es 36
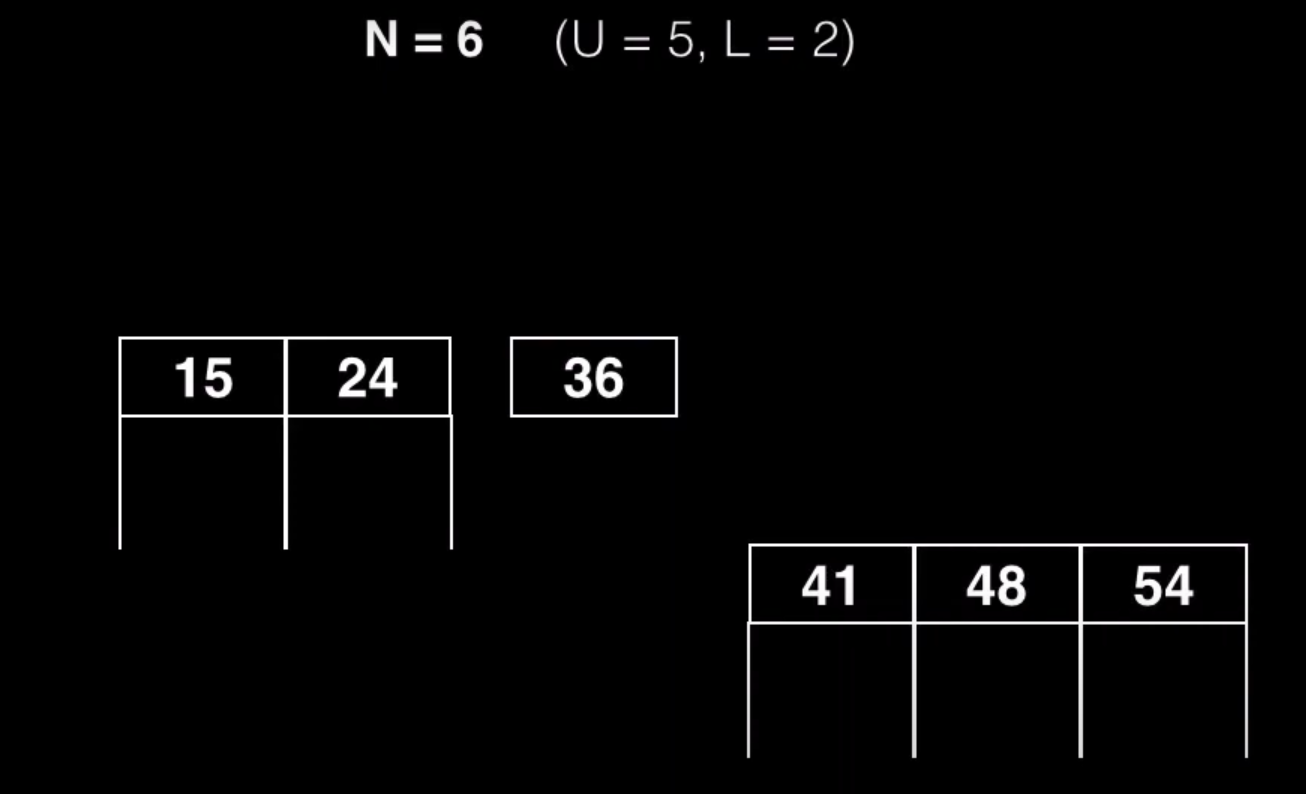
El separar el subnodo derecho hay que tener en cuenta que hay que mover tanto las claves como los hijos que sean superior a L.
División en Raíz
Podemos llegar a tener que realizar una operación en la raíz por alguna de estas dos causas.
- Al empezar con un árbol vacío y al ir insertando claves, se puede llegar a un desbordamiento del único nodo existe que es la raíz
- Como hemos visto anteriormente, un nodo hizo puede provocar el desbordamiento de claves en el padre (exceso de claves permitidas) y esto puede llegar recursivamente hasta la propia raíz del árbol
Es un caso especial dado que no podemos mandar el pivote a ningún nodo padre
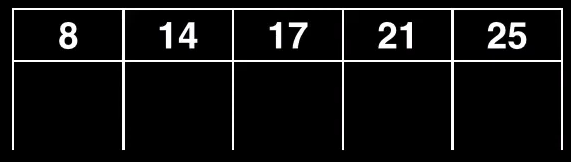
En este ejemplo, buscamos el pivote, que resulta ser el 17
Al fabricar el nuevo subnodo derecho
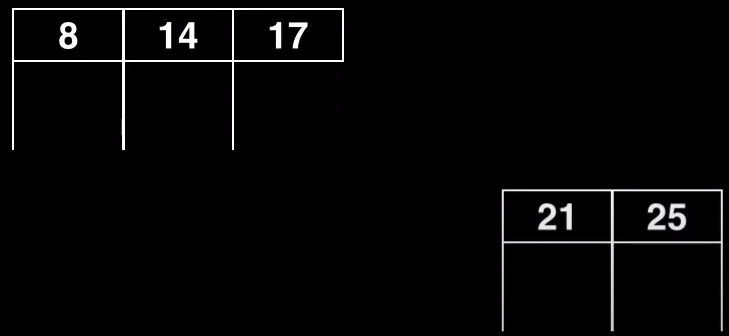
Vamos a fabricar también un nuevo nodo vacío extra que solo va a tener un único elemento, que va a ser precisamente el pivote, y lo convertimos en raíz
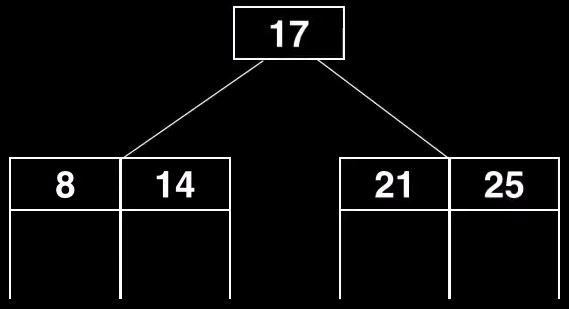
Esta división es un poco especial ya que va a actualizar el puntero root dentro de la clase o estructura árbol.

Pseudocódigo de las operaciones
Estructura
Como para la operación de división se requiere que el elemento ya este dentro del array aunque este sobrepase el límite de claves permitidas, lo más sencillo en lenguajes como java es aumentar la capacidad del array desde N - 1 a N
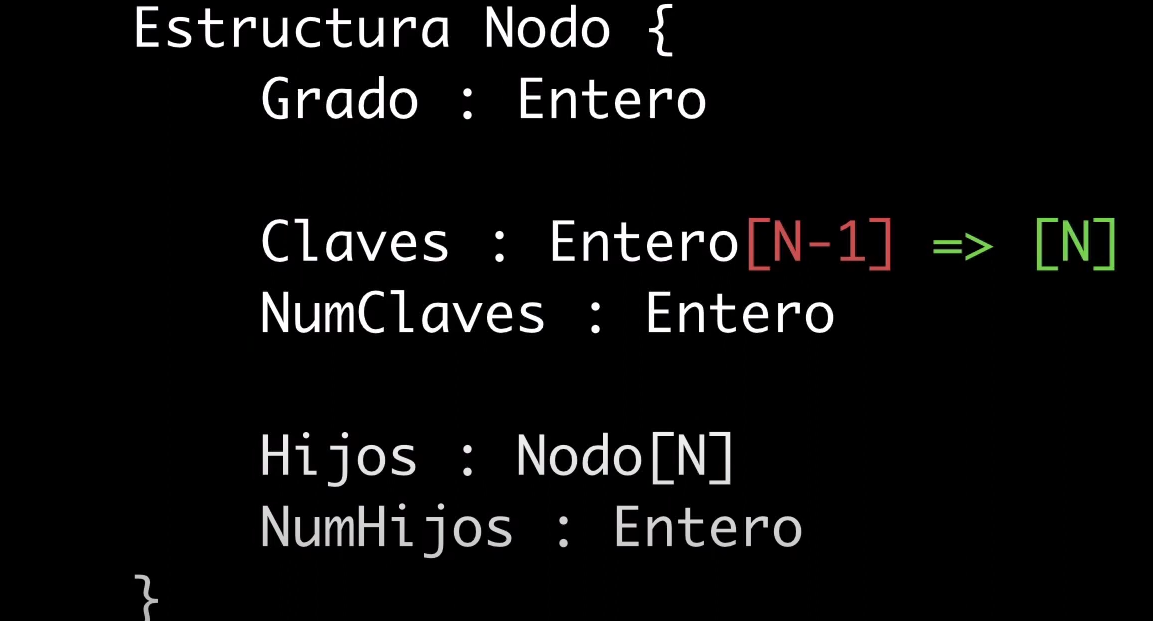
public class Nodo {
int grado; // Grado del nodo
int[] claves; // Claves almacenadas en el nodo
int numClaves; // Número actual de claves
Nodo[] hijos; // Hijos del nodo
int numHijos; // numero de hijos
}Inserción Ordenada
Método para insertar una clave en un nodo de forma que quede de manera ordenada, empujando todos los valores hacia la derecha si hace falta.
El parámetro extra hijo derecho se va a usar luego cuando se inserte un pivote y ese pivote puede que tenga que apuntar luego hacía el elemento nuevo nodo que acabamos de meter, si inserto en un nodo hoja este parámetro será null.
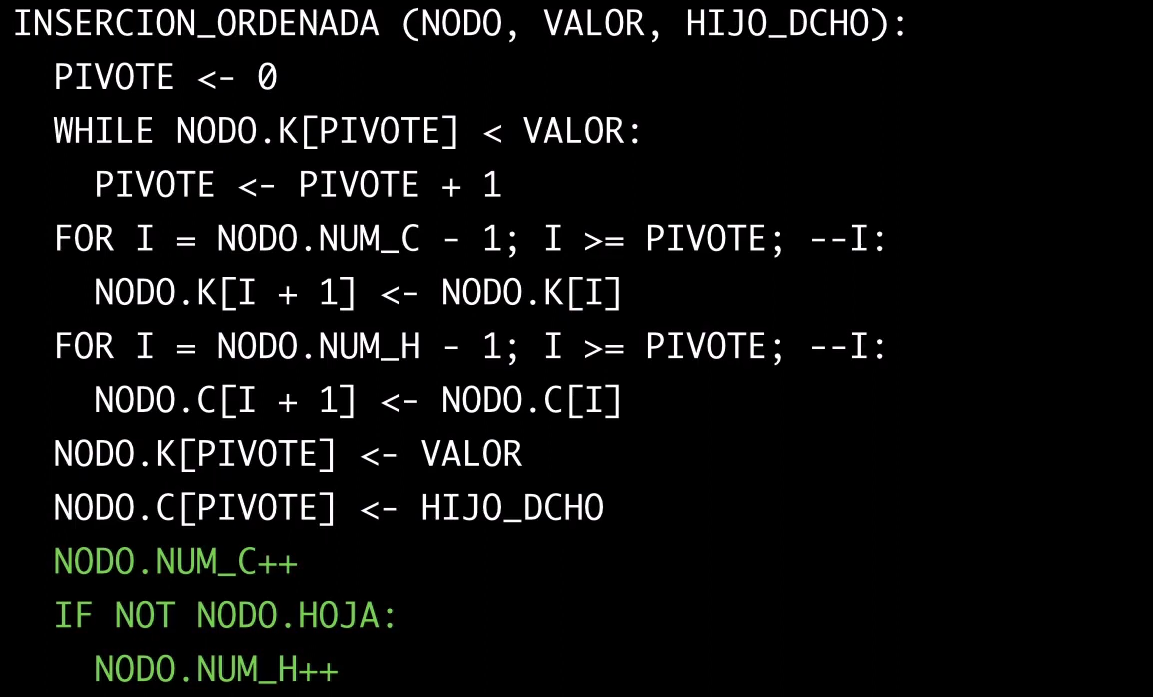
public void insercionOrdenada(Nodo nodo, int valor, Nodo hijoDerecho) {
int pivote = 0;
// Encontrar la posición correcta para insertar el valor
while (pivote < nodo.numClaves && nodo.claves[pivote] < valor) {
pivote++;
}
// Desplazar las claves hacia la derecha para hacer espacio
for (int i = nodo.numClaves - 1; i >= pivote; i--) {
nodo.claves[i + 1] = nodo.claves[i];
}
// Desplazar los hijos hacia la derecha si no es hoja
if (nodo.numHijos > 0) { // Solo si tiene hijos
for (int i = nodo.numHijos - 1; i >= pivote + 1; i--) {
nodo.hijos[i + 1] = nodo.hijos[i];
}
}
// Insertar el nuevo valor y el hijo derecho en su posición
nodo.claves[pivote] = valor;
nodo.numClaves++;
if (hijoDerecho != null) { // Si el hijoDerecho no es nulo, ajustar los hijos
nodo.hijos[pivote + 1] = hijoDerecho;
nodo.numHijos++;
}
}División
Aquí vemos la forma de realizar la división en código que será diferente de la que vimos anteriormente:
En la nueva forma, separamos en el nuevo nodo todo desde el pivote.

Esto lo vamos a pasar hacia arriba para que sea el padre quien realice la conexión entre el pivote y él. Así no tenemos que mantener una relación hacía arriba

public Nodo division(Nodo nodo) {
// Crear un nuevo nodo
Nodo nuevoNodo = new Nodo(nodo.grado);
int j = 0;
// Dividir las claves
int inicio = (int) Math.ceil(nodo.numClaves / 2.0); // Calcular el punto de división
for (int i = inicio; i < nodo.numClaves; i++, j++) {
nuevoNodo.claves[j] = nodo.claves[i]; // Mover claves al nuevo nodo
nodo.claves[i] = 0; // Opcional: Limpiar el espacio en el nodo original
}
// Si no es hoja, dividir los hijos
if (nodo.numHijos > 0) {
j = 0; // Reiniciar índice para los hijos
for (int i = inicio + 1; i <= nodo.numHijos; i++, j++) {
nuevoNodo.hijos[j] = nodo.hijos[i]; // Mover hijos al nuevo nodo
nodo.hijos[i] = null; // Opcional: Limpiar el espacio en el nodo original
}
nuevoNodo.numHijos = j; // Actualizar el número de hijos en el nuevo nodo
}
// Actualizar el número de claves y el estado de hoja
nuevoNodo.numClaves = j;
nuevoNodo.numHijos = j;
nuevoNodo.hoja = nodo.hoja; // El nuevo nodo será hoja solo si el original también lo es
// Actualizar el número de claves del nodo original
nodo.numClaves = inicio;
// Retornar el nuevo nodo
return nuevoNodo;
}Inserción
Método real para realizar una inserción de manera recursiva aceptando un nodo y el valor
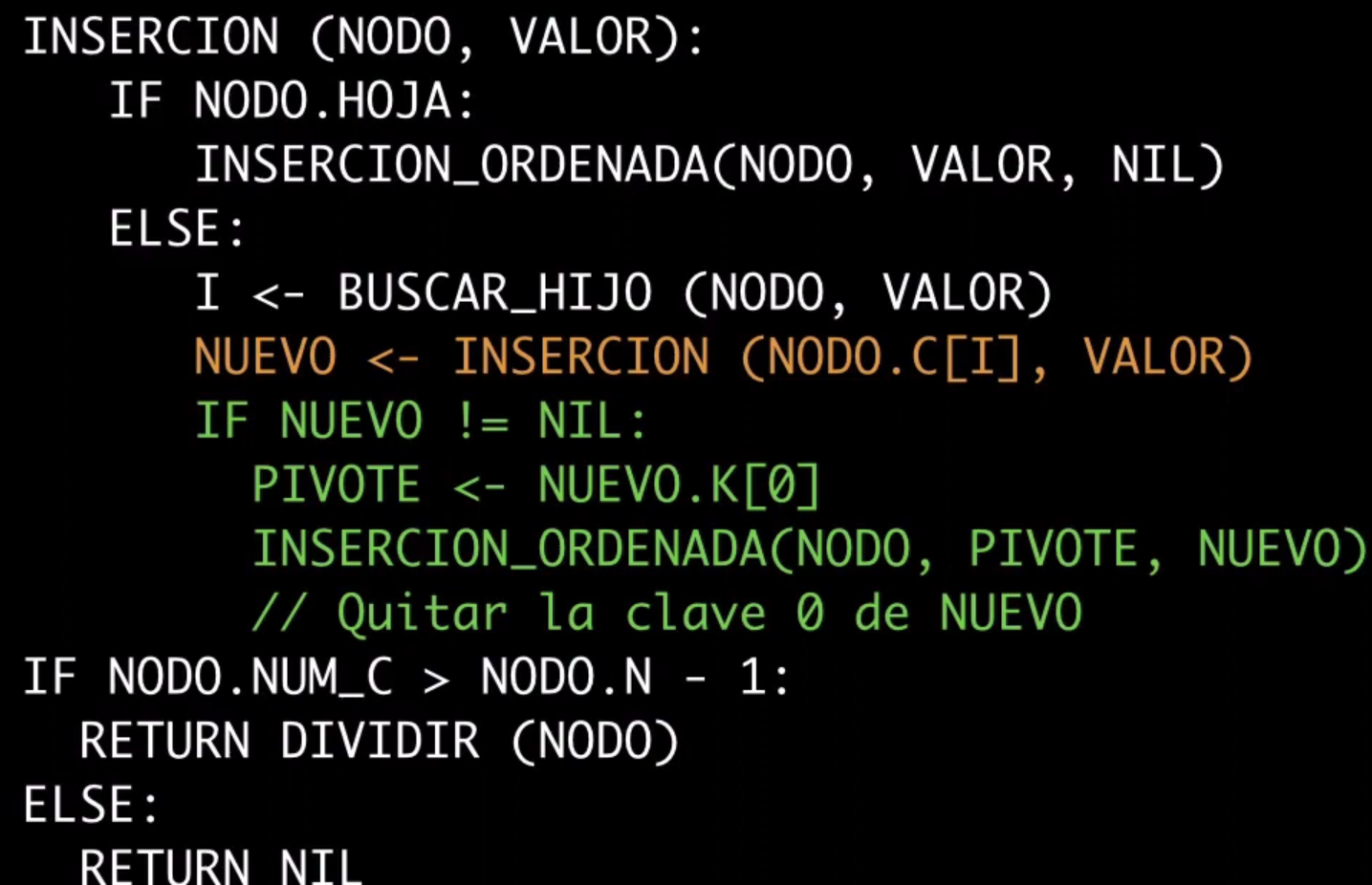
public Nodo insercion(Nodo nodo, int valor) {
if (nodo.esHoja()) {
insercionOrdenada(nodo, valor, null);
} else {
int i = buscarHijo(nodo, valor);
Nodo nuevo = insercion(nodo.getHijo(i), valor);
if (nuevo != null) {
int pivote = nuevo.getClave(0); // Obtener la clave 0 de "nuevo"
insercionOrdenada(nodo, pivote, nuevo); // Inserción ordenada con el pivote
nuevo.quitarClave(0); // Quitar la clave 0 de "nuevo"
}
}
if (nodo.getNumeroClaves() > nodo.getN() - 1) {
return dividir(nodo); // Dividir el nodo si excede el límite
} else {
return null; // Retornar null si no es necesario dividir
}
}